The Universal Digital Collections Cookbook

Introduction
How does one go about creating an universal digital collection? My hub is a result of over 20 years of experience dealing with museums, libraries and archives around the world. There were many lessons learned and failed initiatives but they were not in vain. Our experience has taught us the way forward. Technology has improved to a point where it is viable to create the ultimate collection that will be ever lasting.
- February 2016
Public Domain
The information I've provided here is classified under public domain. I am not claiming any copyrights or inventions. It is based on my body of knowledge gained over the past 20 years. My intent is to help all organizations large and small to get a better handle on the monumental task of preservation and archive and content management. I welcome any feedback.
Obsolete Media

The Cloud Servers

Background
In my 20 plus years working with large institutions, the one most important thing I've learned is that haste makes waste. In trying to achieve something quick, the efforts and resources spent end up being mostly wasted. In order to achieve something long lasting (by that I mean in the order of hundreds of years), one need to take the time and implement wisely such that any work would not be duplicated sometimes later. I've been involved with numerous pilot projects where the idea is to try something new on a limited basis. If it is proven to be acceptable, it would be adopted.
There is a learning curve for any newcomer. The problems of archive and preservation have been around for centuries. Traditional libraries and museums are very suspicious of new technology and rightly so. If the technology is only good for a few decades, that is unacceptable. Such are true of digital media such as CDROM, DAT tape and DVD. The difference now is the cost and density of storage have reach the point where it is almost negligent. With the "cloud" servers, the goal of a truly permanent media storage is at hand.


Design Goals
The main purpose of any collection is preservation. No matter what objects we are concerned with (painting, letters, artifacts, communications...), what is the best way to preserve a collection?
A doomsday scenario. The one way to think about preservation is to imagine the worst case scenario. What if a nuclear war wipes out a significant part of our planet or an asteroid strikes, how will a collection survive? Believe it or not, there are systems in place today to address that very case. The most important and sensitive documents are digitized and copies stored on different continents buried deep in mountains. In addition, there are physical printouts of binary files on paper that are stored as backup for the case when all electronic means are no longer available. These people have concluded that the most reliable form of preservation is still binary codes on printed paper. Think about it, after years of technological advances, trying to reach the paperless office, the simplest and most reliable source is 1's and 0's on paper.
Most collections do not require that extreme treatment. What are the goals of a typical collection?
- long term preservation
- accuracy of reproduction
- full indexing
- secure storage and backup
- security and copyrights
- easy and quick access
- finding aids
- ease of use interface
- simple workflow
- be cost effective
- modular approach
Universal Module Approach
The whole task can be broken down into individual modules.
- Capture
- Index
- Associations
- Storage (cloud server, batch and single)
- Search (finding aids...)
- Retrieval (web access, read only and R/W)
- Security (rights management, data encryption))
- Image Processing
- Web design (front end appeal)
- Workflow
- Intelligent Agent (cache)
- Standards (File formats, Industry standards)
- Backup (automated)
- Physical inventory and management (Long term storage)
- Restoration (as needed)
- Audit trail
A Framework For Implementation
The nice thing about a modular approach is that you need not to implement all at once. The framework is what is important. Once it is established, the pieces can be assembled at your own pace.
Coming up with the proper framework depends on many factors. Such as the type of content, the condition of content, the the value of content, the sensitivity of content etc.
Funding and Human Resources
As with any project of this magnitude, the funding source must be addressed up front. There is no point in starting a long term project without full financial commitment. The amount required depends on the scope of the project and the time frame required. Once a project is put in motion, there are a few options as to allocating resources to get the job done.
For example, the prepping and scanning may be outsourced to a Service Bureau who can do the task faster and cheaper.
A minimal staff of people with an assortment of skills are required. Teamwork is a key component to success.
Getting the right equipment to match the tasks and purchasing the right software that will be long lasting.
Prioritize Contents
Another key decision before embarking on a project is to prioritize your content. What material will be processed first? It is not possible to do everything together. There should be a priority where certain type of content (perhaps most important) be done first. Within the type of content, the same applies. You may choose to do only a subset of that content type before moving to another type.
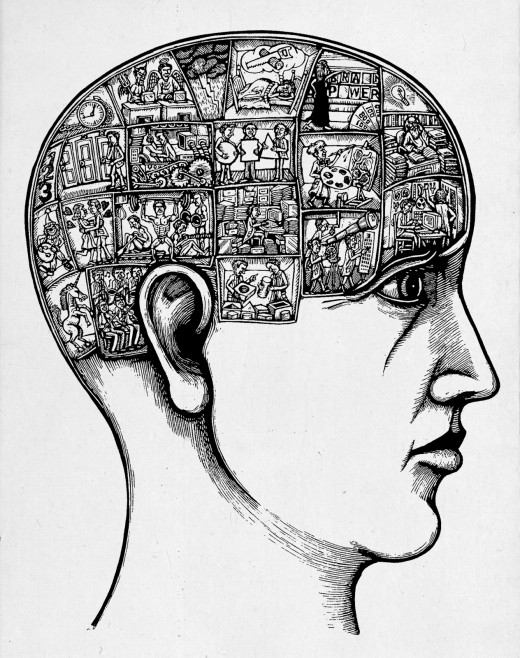
Model After the Human Brain (A Detour)
If you think about it, our human brain is the ultimate archive. It contains all the information of our whole life experiences. It is accessible via our memory though some are better than others. It is compact and it is accessible via multiple triggers (our senses). It is organized in a very sophisticated form that we are just beginning to understand. It is dynamic and changing. It has built in redundancies in case of disaster such as trauma injuries. It is the perfect archive.
We can try and model a collection after our own brain and take advantage of what is known. Our brain works on intuition more than on exact data. Our brain relates many attributes to create a "memory packet" that can be easily recalled via various triggers. That is because we have created numerous neuron connections to the same event. Instead of recall only by a name, we can recall by a smell or a sensation or a color or a sound etc.
In our own daily activities, if we are looking for a document in our file system, we usually think of a name or a category to narrow our search. We alphabetize the name so that we can locate it easily and quickly. That works fine if the document we are seeking is indexed properly or filed in the right folder. If we are looking for a specific document that are filed in a different folder, that is much harder. Fortunately, our brain can do some analyzing and guess as to where that document may be. Technology can help also. We can digitize the files into searchable PDF files. Once we have all the files in place, we can search on a particular name or phrase that will pull up all occurrences of that term. This will help locate the document assuming you can fine a term unique enough to that collection.
Workflow (A Sample Implementation)
Let me take you through a simple workflow for a specific collection - say paper documents (8.5 x 11) letter format. For this discussion, let's assume we are talking about Personnel records. Assume you have a file cabinet with folders of documents stored in alphabetic order by Last name, First Name. Each folder contains an assortment of paper records for a given employee. Being personnel records, they are sensitive and must require access limitations.
Here is the workflow and programs to convert them to a digital archive. (Items in bold are specific hardware/software recommendations).
1. Document Prep Step - All folders must be prepped first to remove any staples or post-it notes and repaired as necessary any tears etc. Each folder will be prepped from fist page to the last page.
2. Document Scanner - The folders are put through a document scanner such as a Kodak desktop scanner with CapturePro. The scanner should be production grade with reasonable speed and able to scan duplex.
3. Quality Assurance - After scanning to a TIF format file, each page is examined by a Q/A operator using a standard software program such as Microsoft Office Document Imaging. The Q/A operator will be required to check for quality of the scan, delete blank pages, rotate page as needed and identify any defects.
4. The Scan Operator will perform any corrections as needed.
5. A batch operation will be performed on a set of files (perhaps all scanned during one day) and convert all TIF files to a searchable PDF file. The Adobe Acrobat Pro is a good program to use. This operation may take a while to process and may run overnight.
6. An index Operator will create a CSV file containing the Name (index field) of each folder along with the file name of the PDF file. There exists utilities that will help with this such as ImagEntry. This utility will insure accuracy of data entry by creating a double blind process.
7. A good Content Management System for documents is Cabinet SAFE. This product is easy to use and contains various access protection mechanism and encryption of data. It will also allow web clients to login to access the data anywhere.
8. There is an option to batch process a set of documents and import them into this system. An administrator can setup users based on various access privileges and assign login password.
9. Once completed, one can login as a user and verify that all the records were imported properly. The users also have various search capability to help locate the folders. Besides searching by the index info, there is the option to search across the whole set of records to find a particular term. The system will return all the occurrences of that term.
10. Finally, the system has an audit trail capabilities that can generate reports on access activities based on users.
It is desirable to keep all original content in storage as long as possible. There are data storage services such as Iron Mountain that will store boxes of content and track them with bar codes.
Also, besides the simple data entry, there are several options to assist with indexing. You can use a cover sheet that includes the index fields and let the Capture software pick them up at scan time or alternatively, you can choose to use a barcode scheme to create the index.

Document Prep (Sidebar)
This is an important step not to be overlooked or belittled. As with any assortment of documents, you will find there are exceptions. There may be over-sized paper, card boards, punched holes, coffee stains and assorted clips and hand written notes etc. The document prepper must handle all these encounters and fix them in a way that will allow easy scanning and not cause damage to the equipment or paper jams. It is tedious work and requires paying attention to details. It is not a high paying job and yet it is essential to creating a quality end product.
Depending on the source material and how they were stored, there are cases where the original content may have been damaged by water or mold or fungus. Prepping of these content require special skills and wearing gloves and masks and patience.
Rule Of Thumb
For paper documents, a typical box will contain 2000 pages on average. A pallet will hold 32 boxes. Typical Service Bureau will charge 10-12 cents per page. This average $200 per box and $6400 per pallet. In deciding whether to outsource or do in house, this is a good rule of thumb. A service bureau will be able to turn around 32 boxes in about 2 weeks.
If you have only a few boxes, the decision is simple. Do it in house. If you have 32 boxes or more, go with a service bureau. They are gears to handle large volumes and they employ trained workers that are detail oriented. It is cost efficient and a win win.


Sound Practices
- Keep the original if at all possible.
- Digitize the content at the highest quality possible.
- Quality and accuracy should be emphasized through out the process.
- Simple workflow is best.
- Adopt standards.
- Ease of use should be a design goal.
- Security must not be an after thought.
- Don't put your trust and assets in one basket.
- Pay attention to details.
- Never duplicate work.
- Teamwork allows for redundancy.
- Hire people that cares and have the good work ethics.
- Use gloves when handling original documents, photos or film.
- No food or drinks allowed in the work area.
- Use pencil only (no ink pens)
- Store originals in a cool and dry place and most importantly above ground.
- Use Archival quality folders (store documents vertically)
A Photo Archive Workflow (Example)
As another example, I am currently a P/T volunteer at the local Archives in Westchester County. They have a large collection of photographs going back almost 100 years. A simple workflow to capture them are as follows:
1. Use an Epson Expression Tabletop Scanner to capture originals at 400ppi with 24 bits color and store as TIF format files to a folder \Archive\
2. Create a logical naming convention for the collection. Each file must have a unique file name. It could be as simple as ABCDnnnn where nnnn is a sequence of numeric numbers. This particular scheme fits with the Epson scanner software. It is configured to scan using this type of scheme and will save time during production scanning.
3. Sort the photos by size and orientation. Make cardboard jigs to the sizes of the photos. Scan the photos in sequence.
4. After each scan, open the image file with PhotoShop to verify the scan and make sure the orientation is proper. Save the image to a different folder named \JPG\ and select the highest compression setting.
5. You can optionally use Microsoft Access to create a simple database containing the name of the photo and some related index information such as photographer, year, attributes etc. and a link to the JPG file. This file can be exported to a CSV file for future imports to other Content Management system.
This simple workflow can produce a large amount of content for archival purposes. Given current hardware, one can process up to 100 photos per 8 hour work day which amount to 25,000 per year.
Summary
This is my contribution to help promote good preservation practices. There are many aspects to this topic but none more important then getting the process right. If the process is "right" all other concerns or issues will fall in place. Don't be afraid of the unknowns. Many institutions, out of fear or suspicion, decides to do nothing or wait till the next breakthrough. The problem is, the longer one waits, the probability of disaster is increased. As with any original content, a fire or flood or tornado... maybe the death sentence and lost of content forever.
This cookbook is the starting point. It is a guide to help all organizations to think about what they value most and start marching in the direction that will bring them security and peace of mind. Remember, it is OK to ask for help and guidance and seek out a second opinion.
Let me know by way of comments and feedback if you find this helpful. Thanks for reading.
Some Related Information
- My Career at IBM Research
I was active from 1983 till 2002 working on some exciting projects at IBM Research. - Adobe Acrobat Pro DC Review & Rating | PCMag.com
Acrobat has always towered above all rival PDF software, and the latest version is the best upgrade in years. - Document Management Software | Cabinet SAFE
Go paperless with enterprise document management software & AP solutions from Cabinet. Save time, save money. In the cloud or installed. - Safe Storage White Paper
- eBizDocs Document Management Solutions; Albany, NY
eBizDocs, an award-winning leader in electronic document management solutions, document conversion, intelligent data capture and scanner sales and service. - Image Processing for the web
My tutorial on some basic image processing techniques.
© 2016 Jack Lee



")



