Data Masking Techniques

Abstract
Large organisations have vast needs of valid, relevant and contextual data for testing their myriad applications. Due to the privacy laws prevalent in most countries, the data has to be masked. The most apt and applicable data that can be obtained with little expenditure of effort and cost is by utilizing the production data. Utilizing production data for testing has both advantages and disadvantages. What is not arguable is that if production data is used in test environment, it has be masked (or greeked as some call it). There are different techniques for masking data. This article examines the test data generation process in brief and the role of data masking in it. It will examine the details of various data masking techniques. It will finally look at one possible data masking process flow scenario.
Test Data Generation
Test Data Generation is an important part of testing. This is done by various means. Data could be artificially generated for each run or aggregated from all or some of the previous runs or copied from production to test regions and used.
For generating test data artificially, the concept is that it will mimic the production data. Modern organisations have hundreds if not thousands of data stores or databases. There are many interfaces and dependencies between each of them. Most of the data has dependencies based on business cases rather than through rules enforced by other means, which means to create a set of data the generator must have access to business rules engine (and in some cases they could be embedded piecemeal in the thousands of programs that are running in production system). So test data generators are not always useful if the data is to be used for business rule oriented applications or application systems which have grown organically without a proper plan.
Test Data Management Center Of Excellence
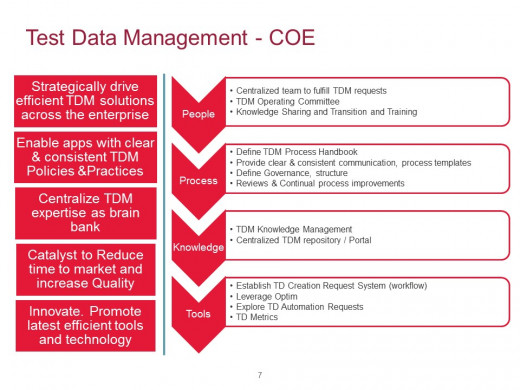
Considerations for Test Data Generation Solutions
Most organisations have to consider the following while selecting the test data generation process they would like to follow.
- For any large-scale system, it is difficult to create sufficient and sufficiently diverse data to fulfill all scenarios. So the first consideration is whether the test data generation process really addresses this or not. in short, not only both quantity and quality are important, even diversity is important.
- Sometimes production data is not available - this could be due to the fact that this is the first run or this is the first run of an entirely new version of an existing software. So test data has to be synthetically generated. There is no other choice.
- Does the data generation include interaction with live data - It may directly use the production data, use the masked production data or use production data as a seed and generate synthetic data. If this is the process then all aspects have to be examined to see if there is any chance of data breach and data contamination.
- Some large-scale systems use many computing platforms as well as operating systems. Some applications are on Mainframe, some on AS400, Some on Linux boxes, some cloud computing, some on PCs. Is the test Data generation tool an end to end solution?
- The other option is to make sure that the entire testing is very secure so that there can be no data breach so that no anonymization (masking) is required. This is theoretically possible but almost impossible to implement as the cost and effort will be high due to the constraints this will process will entail.
- The anonymization process is fraught with its own challenges. It should be in a secure environment. It should be reverse engineering proof.
- The data should be realistic. A name like Mike Hussey cannot be changed to garbage by substituting letters resulting in say Njlf Ivttfz which means nothing.
- There should be consistency - if a query for first name Mike resulted in 20 records the care should be taken that what ever Mike is changed to, if queried, should result in retrieval of 20 records.
- The name change should not result in male names becoming female names (This is not a strict requirement but a prudent requirement)
- If multiple applications are using a set of databases with referential integrity then any data generated mimicking these databases should have the same referential integrity for the same records. This is probably where most of test data generating suites excel. They can parse all the databases and map these kind of requirements and take of it while generating the data.
- The errors that are in the production must continue to have errors even in the test environment. They must be similar to the original errors in the production and must not be such that they can be reverse engineered to know the original error.
- Maintainability of the data - how often can this be refreshed to sync with production data. if the effort is huge to keep the data in sync then we should consider the effect of the same on testing.
Based on these and other considerations, the correct tool has to be selected.
The Test Data Management Process Flow
Initial Setup
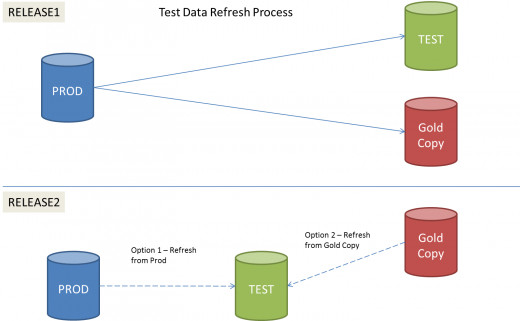
- All Production data stores are identified and approvals obtained to make a copy. This could be a one time activity or done on an annual basis. This process of making a production copies can be a candidate for automation.
- The sub-set of data from the copy is extracted. To this any manufactured data is added to create a Gold Copy. This process of manufacturing the data is also a candidate for automation and this suite is maintained.
- The Test environment is updated with an overlay of the Gold Copy prior to the start of the testing phase
- At the end of testing phase, if any data is manufactured for testing specific cases, these can be used to update the gold copy.
- This gold copy can be copied to various other regions at the start of testing in those regions.
Implementation Approach for first run
- A pilot is completed by selecting a couple of applications and generating test data for them. If that passes muster then the following steps apply.
- All data stores are identified
- Finalize approach to obtaining copy of production data
- Identification and Prioritization of Application Groupings for Masking and sub-setting
- Obtain copy of production data
- Installation, Setup and Configuration of Masking and Sub-setting Tool
- Data Masking and Sub-setting Processes and Procedures Reviewed, Updated, and Approved
- First Grouping Sub-setting and Masking Completed
- Core System Datastores Sub-setting and Masking Completed
- Multiyear Project Datastores Sub-setting and Masking Completed
- Preliminary Gold Test Copy Completed
- Validation of Preliminary Gold Test Copy
- Final Gold Test Copy Completed
- All datastores as identified in scope of this project have been sub-set, masked, validated and loaded into any one Environment. This gold copy is copied to other regions as well.
Operational Process Flow of Test Data Management
Intake
- Analyze Release Calendar and Publish Data Milestones
The Data managers will analyze the release calendar and determine the data milestones. The release calendar holds cut off dates for all submissions.
- Analyze Requirements
The Requestor will analyze the requirements and do preliminary data mining to determine if there is a need to request data for the release, or if it is already available. They also analyze any dependencies that might exist with their downstream systems, Trading Partners or external Vendors. If Production data is needed they will submit a request for Masking directly to the Masking Team.
- Submit/Resubmit Data Mining Requests
The Requestor will submit the Data Mining Requests to the Data Mining Team. .
Data Mining
- Analyze Data Mining Requests
The Data Mining Team will analyze database changes with respect to the Application Design Specification (ADS), before a release even begins, to determine if updates/modifications need to be made to the existing data mining queries and to determine if any new queries need to be developed. The Data Mining team will also analyze the Data Mining Requests and research already existing data to see if what they have can satisfy the data mining request. The data mining will performed primarily towards the public use accounts identified. If the data cannot be satisfied from there, the exclusive use accounts will be mined. Prior to using any exclusive use accounts permission to do so is required for the account owner.
- Communicate data availability
It the data already exist and the team will communicate to the Requestor via email that the data is available. The Data mining team does not communicate when testing can actually commence, only whether existing test data was found that meets the request.
- Communicate data non availability
The Data Mining Team will recommend accounts that can be modified to support the data needs if data is not available for testing. They can in addition if a copy of an account is feasible and complete the Copy request form for submission to the Data Masking Team.
Data Masking
- Mask data
The Data Mining team will hand off the request to the Data Masking team if the data requested is production data. The Data Masking team will mask information such as Account numbers etc. (The process flows for this process are provided separately).
Manufacturing:
- DRF Corrections and Updates
The requestor will make updates to the DRF (Data Request Form) to address the data that was not available, sometimes based on recommendations or suggestions communicated by the Data Mining Team.
- Analyze DRF
The Data Manager team will analyze the DRFs to determine if there is sufficient information to start the Data Manufacturing process. They will check with the Requestor to make sure that they have reached out to the Mining team in case the data is already available.They will check for volume and plan according to what projects are ready to go.
If the request is a “late request”, meaning the date milestone for Grids (data templates) being due is passed, it is brought thru the review process (template review meetings, added to the data plan and supported as soon as possible. The task(s) are identified as late data requests on the data plan so that metrics of the volumes of late data requests per test phase per release can be gathered and reported to management.
If the DRF does not have sufficient information to start Data manufacturing it goes back to the Requestor that will have to revise and rework the DRF before submitting it again.
- Approve DRF# in the approval tool
If the DRF is deemed sufficient to start Data manufacturing, the Data Manager will approve the DRF# and Data Manufacturing can start.
- Create and Submit Data Templates (Grid)
The Requestors are asked to submit their Data Templates (Grids) if the DRF is approved by the Data managers. The Grid contains detailed information on the data that is requested for testing.
- Preliminary Review of Grids
The Grids are reviewed by the Data Loading team to ensure that attributes and values are correct. If the Grid does not pass the review it is passed back to the requestor for rework.
- Final Review: Data Gathering Session
Once the Grid has passed the preliminary review it will be going through a Final Review where the Data Managers in collaboration with representatives from the Data Mining Team, Data Loading Team and Requestors will determine dependencies and prioritize the work.
The Data Gathering session is held by the Data managers, and the outcome is the Data Document outlining the details of the data requests.
- Prepare Final Revised Data Set Up Plan, plug in data and store in Sharepoint.
The Data Managers will prepare a Data Set Up plan based on the Data document and plug in data. The plan will include early data seeding tasks that are not release code dependent as well as code dependent tasks that must wait to be created until after the environment build out is complete. The data manager uses the release management published critical project list for the release as well as testing cycle requirements and dependencies gathered from the requestors when prioritization data tasks and resources within the data set up plan.
- Review Data Set Up Plan
When the plan is available, the Requestors will review it to ensure that the schedule and details of the Data Plan will meet their testing timelines. If it doesn’t they will communicate back to the Data Managers and they will revise the plan accordingly.
- Load and Validate Data
If the review of the Data Setup plan is passed the Load/validate process can begin by the Data Loading Team. They will manufacture the data using the applications and running batch jobs/scripts. This process can take up to X days to complete and the progress is communicated to the Requestors by updating the data set up plan for each step when completed. The process can be delayed due to dependencies on Requestors, Trading Partners and Vendors that might have to perform their own steps in order to complete the cycle.
- Deliver Test data
Communication is made to the Requestors, using the data setup plan, once the test data is manufactured and testing can begin.
- Update completion date in Data Set Up Plan
The Data Set Up Plan completion date is updated once the data is delivered to the Requestors.
- Submit Request for Automation Enhancement
If, during the Manufacturing process, something has been identified as re-usable and possible to automate, an Automation enhancement request is submitted to the Automation Group.
Automation:
- Intake Process for Automation
The automation requests will be processed by the Automation Group.
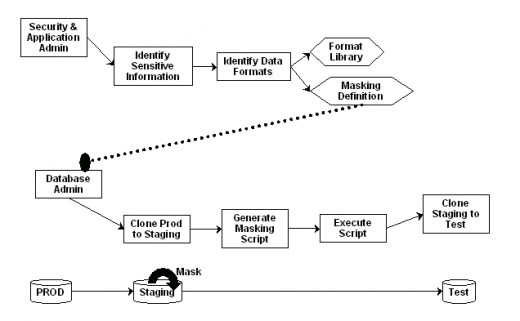
Data Masking Process Flow
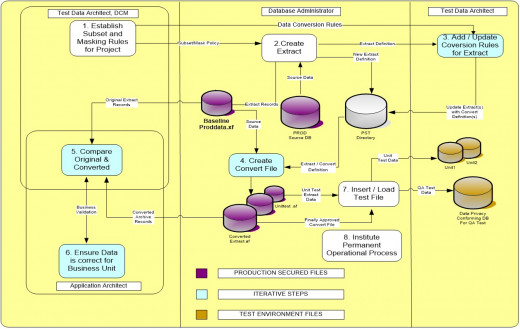
Data Masking
Do you use Data Masking at you site
Data Masking
Data masking
Data Masking is the replacement of existing sensitive information in test or development databases with information that looks real but is of no use to anyone who might wish to misuse it.
Firstly it should be determined what data has to be masked and what type of masking is required.
Some data cannot be masked as it becomes useless when there are even small changes.
Some data can be slightly modified – for example test data to test a bug fix has to be masked as little as possible else it becomes useless. But there might be fields here that can still be masked. If no masking is possible, then care is taken that these processes happen in an environment that is secure.
When the testing is done internally and the data does not have visibility outside the organisation, then there is a possibility of disregarding masking. This is not a valid assumption as accidents happen and data breaches can occur. In this case the data masking requirement is higher than the previous case.
If the testing is outsourced then the data masking requirement is stringent.
There are different types of data masking architectures – On the fly or in situ. Both have their advantages and disadvantages.
Data Masking Types
Architecture
| Advantages
| Disadvantages
|
|---|---|---|
On the Fly
| The data is never present in an unmasked form in the target database
| Errors will disrupt the proces
|
Once the changes are done and the target database is populated, it is difficult to mask another field if so decided
| ||
In Situ
| Possible to apply additional masking operations later.
| |
Masking operations are separate from the copy process so existing cloning solutions can be used
| Data is present in an unmasked state in the target database and hence additional security measures will be required
|
Advantages and Disadvantages of Data Masking Architectures
Data masking Techniques
Substitution
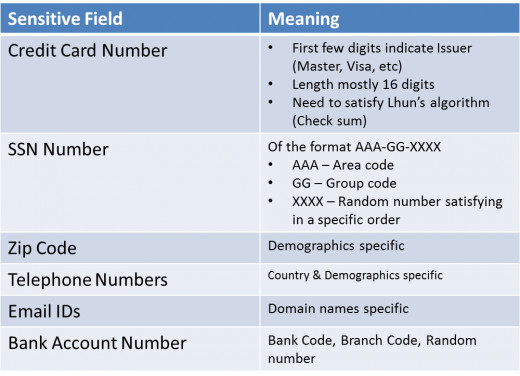
Randomly replacing contents of a column or field with similar looking information but unrelated to the real details. An example would be to replace the first and last names with values from a customized look up table. This substitution method needs to be applied for many of the fields that are in DB structures across the world, such as telephone numbers, zip codes and postcodes, as well as credit card numbers and other card type numbers like Social Security numbers and Medicare numbers where these numbers actually need to conform to a checksum test of the Luhn algorithm.
The disadvantage is fairly obvious. The substitution data should be large so that, for example, one first name should have only one substituted value or else there could be issues. This is mostly taken care by most commercial software.
Shuffling
Shuffling is similar to substitution except that the data is derived from the column itself. The data is randomly shuffled within the column across the rows. This is somewhat a risky maneuver. A what if analysis could result in reverse engineering the data. Also if the shuffling algorithm is found out, the rest of the data can be easily un-shuffled. Shuffle method is suitable for large tables.
Number and Date Variance
When dealing with financial data like payroll, it might be good to apply a percentage of plus or minus 10% some on the higher side and some on the lower side. They would be different but not too far from the real values. While dealing with dates, an plus and minus 120 days could effectively disguise a birthday and hence the PII. This would still preserve the distribution.
Encryption
This technique offers the option of leaving the data in place and visible to those with the appropriate key while remaining effectively useless to anybody without the key. This is not a major advantage as the loss of key could compromise the data. Subsequent re-encryption would not help as the earlier copies are all still compromised. The formatting is generally destroyed during encryption. Also the testers need to be granted full user rights. Recent advances in encryption have lead to emergence of FPE (Format preserving Encryption) algorithms have been developed based on AES algorithm.
Another issue is deciding what type of encryption is to be used. Any encryption can be broken, given time and enough effort is placed. Also GPU decryption techniques and other latest advances in decryption methods have made the lifetime of encryption codes smaller.
Nulling Out/Truncating
Simply deleting a column of data by replacing it with NULL values is an effective way of ensuring that it is not inappropriately visible in test environments. unfortunately it is the least preferred option.
Masking Out Data
Masking data, in this case, means replacing some data with generic masking characters like x. So 1234 6454 0020 5555 would look like 1234 XXXX XXXX 5555. This removed the sensitive and meaningful content from the data still preserving the format and look and feel of the data. Care should be taken to mask the appropriate data. masking the first four characters of a credit card would mask the issuer details which may or may not be desired. Similarly not masking enough digits in an SSN or CC numbers could lead to easy reverse engineering of the numbers as they all utilize checksum algorithm.
Row Internal Synchronization
The Row-Internal Synchronization technique updates a field in a row with a combination of values from the same row. This means that if, after masking, the FIRST_NAME and LAST_NAME change to Mike and Hussey then the FULL_NAME column should be updated to contain Mike Hussey. Row-Internal Synchronization is a common requirement and the data scrambling software you choose should support it
Table Internal Synchronization
Some of the data items may be denormalized due to repetitions in multiple rows. If, for example, the name Mike Hussey changes to Albert Wilson after masking, then the same Mike Hussey referenced in other rows must also change to Albert Wilson in a consistent manner. This requirement is necessary to preserve the relationships between the data rows and is called Table-Internal Synchronization. A Table-Internal Synchronization operation will update columns in groups of rows within a table to contain identical values. This means that every occurrence of Mike Hussey in the table will contain Albert Wilson. Good data anonymization software should provide support for this requirement.
Table-To-Table Synchronization
The same concept as above but extended across different tables which are not normalized. A variation of this is Table to Table Synchronization on primary Key, Table to Table Synchronization via third table, etc . Synchronizing Between Different Datatypes - when the data type of the same field in different tables has different Datatypes in different tables.
Cross Schema Synchronization, Cross Database Synchronization, Cross Server Synchronization, Cross Platform Server Synchronization are a variation of the same theme.
Data masking Workflow and examples