Database Technologies

It is important for a business to be able to make decisions based on the information available. The challenge is often that this information resides in a multitude of dissimilar systems that don’t play well together. There are a few technologies to help companies make sense of it all. By keeping these technologies in mind you can enhance the overall performance of a large enterprise database system to properly structure its architecture.
Data Warehouses and Data Marts
Data Warehousing aids in this endeavor by consolidating these disparate data sources into one single source. Data warehousing, abbreviated DW, is a collection of historical, summarized, non-volatile data designed to support management decision-making. Data warehouses contain a wide variety of data that presents a coherent picture of business conditions at a single point in time. This is truly an enterprise database due to its sheer size and need for security levels.
Because of the size and security considerations, data warehouses are not only difficult to implement, but undertaking a project to create a data warehouse is a time consuming and daunting task. Development of a data warehouse includes the development of systems to extract data from operating systems plus installation of a warehouse database system that provides managers flexible access to the data.
The term data warehousing also generally refers to the combination of many different databases across an entire enterprise. One should keep in mind is that data warehousing is a process, not a product that is used for assembling and managing data from various sources for the purpose of gaining a single, detailed view of a part or all of a particular business. Not only is it a process that involves combining different databases together, but it also needs to have a proven framework or blueprint to be successfully implemented into any business. Without a proven framework for your data warehouse, you could be storing information you do not need or data could be in a locations that make it difficult to find. You also have to remove any duplication of the same data to maintain integrity.
A Data Warehouse is a collection of data gathered from one or more data repositories to create a new, central database. Bill Inmon, who is recognized as the “father of data warehousing”, defines a data warehouse as “a subject-oriented, integrated, time-variant, non-volatile collection of data in support of management’s decision-making process”. Ralph Kimball, another noted authority on data warehousing, defines it more simply as “a copy of transaction data specifically structured for query and analysis”. Both of these definitions show that a data warehouse is a collection of data separate from the databases that support the day-to-day operations of an organization, and that it is specially designed for the purpose of producing reports.
However, data warehouses by themselves are not entirely useful by everyone in the corporation. For this, a data mart is needed. Data marts are the localized views of a data warehouse, which break down the data into usable chunks by the specific group that actually owns the data. For instance, marketing probably couldn’t care less about what engineering’s issues and resolutions to a design flaw are. Because of this, data is filtered according to the needs of the specific department.
Some companies do not want to undertake the daunting task of creating a data warehouse, so instead they create several standalone data marts. In these cases, the data marts may hold some extra information, but even the databases in these cases are specifically tuned to the needs of the department rather than the enterprise. This is called an independent data mart, whereas the data mart that relies on data from the data warehouse is referred to as a dependent data mart.
A data mart is a repository of data gathered from operational data and other sources that is designed to serve a particular community of knowledge workers. In scope, the data may derive from an enterprise-wide database or data warehouse or be more specialized. The emphasis of a data mart is on meeting the specific demands of a particular group of knowledge users in terms of analysis, content, presentation, and ease-of-use. Users of a data mart can expect to have data presented in terms that are familiar. Most people using these terms seem to agree that the design of a data mart tends to start from an analysis of user needs and that a data warehouse tends to start from an analysis of what data already exists and how it can be collected in such a way that the data can later be used. A data warehouse is a central aggregation of data (which can be distributed physically); a data mart is a data repository that may derive from a data warehouse or not and that emphasizes ease of access and usability for a particular designed purpose. In general, a data warehouse tends to be a strategic but somewhat unfinished concept; a data mart tends to be tactical and aimed at meeting an immediate need.
It must be pointed out that a Data Warehouse is not intended to act as a transaction processing system. The data is intended for analysis and may consist of information mined from sources as much as one or two weeks earlier. This makes it unsuitable for time critical operations, such as inventory control. It is perfect, however, for such tasks as historical trends analysis and forecasting.
Data Warehouses are now becoming more common as large, long established, companies have identified requirements to access and analyze huge amounts of data they have been collecting for several years.
With corporate mergers, customer/product requirements, IT-department downsizing and technological advances, many companies find themselves with several independent data marts (called “data silos”) that they then integrate into a single data warehouse. This effort is often referred to as “data mart unification”.
OLAP
The term OLAP was first used in a white paper written by Ted Codd, the father of the database normalization rules. While this paper proposed a number of features that are now only loosely associated with OLAP, it established the basic feature of OLAP processing, that of multidimensional views. OLAP products can view an enterprise as being multidimensional in nature. For example, profits could be viewed by region, product, time period, or scenario (such as actual, budget, or forecast). Multi-dimensional data models can allow a more straightforward or intuitive manipulation of data by users, including "slicing and dicing".
OLAP applications are typically client/server in nature, with the OLAP server accessing the data on another computer and providing the analysis to the client machine. OLAP systems are typically used to perform commercial and financial analysis, drawing upon previous or historical performance data. OLAP systems typically run against large, low-transaction, high-latency relational databases that are updated relatively infrequently.
OLAP, which was originally an acronym for On Line Analytical Processing, is a set of tools that allows access to data stored in a database. The tools create a gateway into the server that gives analysts, managers, and executives a method to access a wide variety of views to specific data within a database. OLAP is especially used for analysis of consolidated data normally found in an enterprise data warehouse or data mart. OLAP is also more tuned to analytical and navigational activities such as calculations, trend analysis, and drilling down.
This is a tool for extracting specific subsets of that data for more thorough analysis. It will provide whatever level of detail you require for your task at hand. One instance may result in detailed sales figures while another will provide monthly summary data, broken out by region. It all depends on how you request the results be returned. After a query is completed on the Data Mart, the results can be loaded into a document, another database, or a spreadsheet for analysis.
Essentially, OLAP provides a means to produce faster results to complex database queries. Technological advancements incorporated into OLAP are designed to overcome the shortfalls of conducting multi-table searches in relational databases that traditionally can be very slow. OLAP is able to accomplish faster searches by taking a snapshot of a relational database and convert it into dimensional data that queries are run against. The resultant answer to each query frequently takes as little as 0.1% of the time for the same query in a typical relational DBMS (database management system). These tools enable users to analyze different dimensions of multidimensional data.[CSS1] For example, it provides time series and trend analysis views and is often used in data mining.
OLAP is an important application when it comes to data warehousing. With a lot more spatial data being collected in databases today such as sensed images, geographical information, and satellite survey data efficient online analytical processing for that spatial data is in great demand. The chief component of OLAP is the OLAP server, which sits between a client and a database management system (DBMS). The OLAP server understands how data is organized in the database and has special functions for analyzing the data. There are OLAP servers available for nearly all the major database systems worldwide.
Three-Tier Architecture
Two-tier architecture consists of a client and a database. In this infrastructure, the client directly accesses the database for information it needs. In some cases procedures are stored on the database server, so that the requests and subsequent data do not have to travel across the network. In this way, stored procedures reduce network traffic.
Online transaction processing, or OLTP, is a class of information systems that facilitate and manage transaction-oriented applications, typically for data entry and retrieval transaction processing. In this article we will address a "transaction" in the context of computer or database transactions OLTP has also been used to refer to processing in which the system responds immediately to user requests. An automatic teller machine (ATM) for a bank is an example of a commercial transaction processing application.
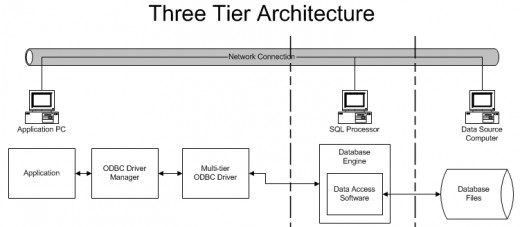
OLTP systems often use three-tier architecture because these systems have a heavier user and transaction load. Three-tier architecture places a tier between the client and the database. This tier runs a transaction processing monitor that interacts with the database for the client. This TP monitor helps to provide higher scalability, availability, and flexibility than a two-tier system. TP monitors do this by providing funneling, fault-tolerance, load-balancing, transaction routing, and heterogeneous transactions.
The first tier, commonly called the “presentation tier,” gives the user or client access to the application. The layer actually presents the data back to the client, and allows the user to interact with the “middle man” or “business services” tier.
The “business logic tier,” or middle layer, is the only tier that can communicate with both the data tier and the presentation tier. Communication cannot occur between data and presentation without this layer. Commonly, this tier conducts calculations, follows business rules, and follows data rules in order to ensure integrity of the data, as well as provide a level of security to disallow unauthorized modification of the database.
The “data tier” does the actual interaction with the data itself, contained within a file on storage media of the server. Most of the time, this tier consists of the actual DBMS that is used to store the data needed.
Simply put, a Three Tier Architecture is an implementation of client server systems that allows a system to accommodate many more users than the two tier architecture will allow. By utilizing the process server, a system can now utilize queuing of requests for data, a more organized approach to data staging, and even implement caching of data to reduce the load on the DBMS.
The user interface module is installed on the client machine, the business logic/application is installed on an application server, and the database is installed on a dedicated database server. This approach allows the brunt of the computing power to be shared among three separate computers thereby increasing the efficiency and speed of the overall system. In addition to speed and efficiency, dissecting the system into three distinct modules allows any one of the individual modules to be upgraded without impacting the operation of the other tiers. This approach also provides a significant increase in operational and maintenance efficiency, making it a very attractive option in modern systems design. Additional speed and efficiency can be very important when developing a system with large amounts of data such as those that require the use of a data warehouse or data mart. . Separating the application functions from the database functions makes it easier to implement load balancing.
ASP
An Application Service Provider (ASP) is a third-party entity that manages and distributes software-based services and solutions to customers across a wide area network from a central data center. In essence, ASPs are a way for companies to outsource some or almost all aspects of their information technology needs. They may be commercial ventures that cater to customers, or not-for-profit or government organizations, providing service and support to end-users. Now, according to ASPnews.com, ASPs are broken down into five subcategories: Enterprise ASPs -- deliver high-end business applications. Local/Regional ASPs -- supply wide variety of application services for smaller businesses in a local area. Specialist ASPs -- provide applications for a specific need, such as Web site services or human resources. Vertical Market ASPs -- provide support to a specific industry, such as healthcare. Volume Business ASPs -- supply general small/medium-sized businesses with prepackaged application services in volume.
Conclusion
As you can see, the efficiency of today’s enterprise systems, and the associated database architecture, can be significantly increased by incorporating OLAP, Three-Tier Architectures, Data Warehousing and Data Marts, as well as ASP. OLAP is capable of providing as much as a 99.9% speed increase in complex data queries. Utilizing a Three-Tier Architecture approach can increase both the speed and efficiency of the system while also making it easier to operate, maintain, and upgrade. Proper integration of Data Warehouses and Data Marts can decrease the overall demands on the system while ASP is a low cost alternative to building a proprietary user interface to your web enabled database applications.







