business systems analysis - implementation

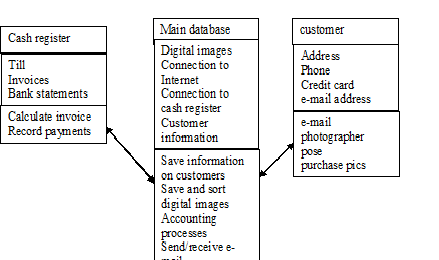
1class diagram for a photography shop
There cannot be enough said about documentation – at every step of the SDLC. At Pfizer they had intranet Treps (Team Repositories) which are only accessible by people ‘with permission from the Project Manager – and not all of them have publishing rights. Here, the drafts are published, to be replaced by the final forms. The original project plan is published. The developer picks that up for guidance on his programming. The developer publishes system guides. The technical writers pick up the proposal to figure out what to put in the system test scripts, and these are published. The technical writers pick up the system tests and the system documentation to figure out what to put in the user manual. Even more technical writers and testers pick up the system tests and users manual to write User Acceptance Testing scripts. FAQs are published there for incorporation into the user’s manual and online help. Of course, the code has to be well documented (if any of you have ever coded in C or C++ you know how a week later you’ll never figure out what the program did). Each published document is approved with three signatures (project manager, technical manager and business manager) when in its final form.
Training is a more complicated decision than it seems. If there are a lot of users, some companies start training in groups of 20 or so quite early in the game, with a prototype if necessary. This is not the greatest idea because users get antsy to apply what they’ve learned and are afraid they will forget it if they don’t start right away (and they’re right). It doesn’t help that most training manuals are skeletal (on the assumption that the user will take notes) – they are too busy doing the hands-on practice to take many notes. So part of the implementation planning should be to make a training manual which is in fact a fast-reference outline of the most commonly used features.
The important users working on the development of the system are of course the original SMEs (Subject Matter Experts). With a large group of potential users, these people on the development team should ‘train the trainers’ – the technical support personnel and professional trainers. Most large companies have computer classrooms all laid out and waiting. We did this at Shawmut Bank – I worked directly with the curriculum developer to get a clear user’s manual and training session plan for the network. If the company has ‘shadow IT’ people, these are great to prepare – they will work one-to-one with their fellow users.
Whether the system is fully new or an upgrade, tutorials are great when built into the help menu; users can spend lunch hours or any other time privately learning the material. If the system is complex, modular tutorials are a great help as a backup after formal training.
Some companies have a ‘tracking sheet’ which identifies all variables and the order they are going to be tested, and a formal script format. The tracking sheet coincides with the ‘test plan’. One writer writes the scripts and a separate one runs them (to watch for omissions, etc.) before the system testers get hold of them. Not only do we tell them what to do, but we tell them what the expected result should be at every step; the testers record the actual results. A test manager doles out the forms and the test run numbers.
Most compilers test for syntax problems, and professional programmers are rarely so inexperienced as to need a walkthrough. But they do ‘act like a computer’ – it’s the first debug technique taught. But instead of writing down the variables, virtually any debugger allows you to step in and out of procedures and to name variables to watch as they change during execution of the code. Usually they are used on a needs basis – if there are runtime errors that the programmer cannot pinpoint, the debugger is used.
Automated testing is becoming popular, but I don’t think it’s very good, and most large companies feel the same. By the time you write up an automation, the system test is done. It’s best for ‘installation testing’ – that’s when the system as a virgin box works fine – now how about the 4 different platforms we handle, and how does it work with the standard desktop applications and OSs we use? So a company will set up ‘test beds’ – a series of computers with all the different combinations of OS and applications used; an automated script then runs each through its usage of the new system, to see if there are any conflicts.
Also on the test beds are test data. This test data should be as large as is possible, with all the idiosyncrasies of the live data. It would be virtually impossible to reproduce. So instead, the company takes a snapshot of the live data and loads it into a ‘safe’ space, so that testers can add/edit/delete data without damaging the real stuff. This test database is used by system and user testers. The only time live data is used is during a pilot.
Testing should include not only the usual uses of the system, but every anomaly you can think of. I didn’t get the nickname “Crash” for nothing. Consider all the possibilities – page 3 of 7 falls on the floor while transporting the papers to the scanner; someone enters the wrong index data; someone neglects to enter a required field; the user gets PO’d and starts banging on all the keys. Developers always assume people are going to do the right thing [NOT…]. I once e-mailed a 57-page error message to a developer. So when planning system testing, every possible scenario should be covered. Many developers will set ‘traps’ and make user-friendly error messages for those traps, which is fine. The system testers should aim for the internal error messages, so the developers know where and how to build traps. We’re having a tussle with a developer now because there are certain functions which, if not done right, just stop the system – no message at all – and the developer wants to leave it that way. Not on MY watch.
Alpha testing is always done in-house and can be quite extensive. IBM has a bunch of college engineering interns that do nothing but alpha-test its products – they play games, mess around with the GUI, write letters and crunch numbers, looking for glitches. This generates the coded versions (like the Kirk, Spock and McCoy versions of OS2). A lot of the things they list in the text as alpha testing – recovery, security, stress and performance – are usually considered system testing.
I’m sure you are all aware of beta testing. If this is not a shrink wrap, beta testing would be set up as a “pilot” – a separate group of people get the whole package and use it on live data. This is only done if it’s a huge deployment (over 1000 users). If it’s successful after 2-6 weeks, another ‘wave’ of users will get deployed.
Systems construction includes UAT (user acceptance testing) feedback and alterations based on the same. During the systems testing, the purpose is to find bugs – whether links perform as designed, whether the application has conflicts with other standard applications, whether the application depends on outside files that must be present. This last one has become a particular problem recently, as many customizable packages call Internet Explorer files. UAT is performed by selected end-users, as SMEs. Here they are looking to see if the application meets their needs, if the terminology is what they use (mustn’t use computerese when the user is a photography shop owner), whether drop-down lists contain all the items they need, etc. Some UAT testers will simply apply the application to their work; others need specific scripts of what to do. Often they will have suggestions for changes that they would like incorporated. At this point, the decision has to be made whether these changes should be made before deployment (which means another run of development, engineering and testing), or whether they can be cataloged and saved for the next version. This decision requires input from users, managers and IT.
Now comes the delicate part – actual installation (usually called deployment). Don’t forget we made a decision much earlier about whether to do this overnight, in tandem with the old system, or with the legacy system waiting in the wings in case of disaster. Many companies require a backout plan in case there are serious problems. Certainly a change management committee would require a backout. Keep in mind that many users never log out – they go home and leave their machines running, sometimes even over the weekend. The trouble is that if the deployment is done transparently, it’s done overnight, or it’s built into the login script. If the legacy application or other applications are open, this can corrupt the system installation. To handle this, most large corporations require an e-mail to all potential users of the application at least 24 hours before the deployment. Some also require a warning a week ahead. AT B-MS there is a team that does nothing else – the Process Manager sends them a copy of the announcement and tells them who the potential groups are (for instance, everyone in Genomics and Biochem). The mailing team has an up-to-date mailing list by department and sends it out. Unfortunately that doesn’t always work, and one night I created a mailing list of 200 people by hand, working with the Novell engineers to find all the people involved. The announcement will tell the user what is going to be installed, what special steps might need to be taken (like a reboot), and what impact the installation will have. Pfizer sets up the installation so you can choose to delay certain installations, choose not to install some, and has some that are mandatory. For the mandatory ones they survey (installation sends a token back to the installer) and remind those who haven’t installed yet.

Phased installation is great for die-hard legacy users – keep the GUI familiar and add functions incrementally.
One of the reasons so much depends on the data dictionary is so that no data is lost or corrupted during installation of a replacement system. A perfect example of this is the DCF database the state of Connecticut created. They’d forgotten a few fields, and so came out with a new version in 6 months. But the developer apparently did not separate the GUI from the tables. So three fields were lost entirely; the data picked up by the new version did not pick up the fields in their original order, and since they had the wrong data type, they got dropped. Now every time we go to discharge a patient, we have to re-enter those 3 fields.
Tutorials keep stressing system and code documentation because someone else will probably do the upgrades. This is another of those ethical questions – many contractors and outsources like to withhold documentation so the company is forced to recall them for upgrades. Ugly practice. And many, many in-house programmers used to avoid documenting their coding so that they couldn’t be fired – this is why that cumbersome COBOL was developed – to force documentation. Even if it’s documented, picking up someone else’s code is a real bear. But if a contracting company/outsource provides full documentation, they will become trusted – and will get repeat business. And if you’re in-house, you will be working on many projects. When two years pass and they ask you for work on upgrading, you will be very glad you documented it, believe me.
Help files can be difficult to develop, but they can make or break a system’s success. Since online help is cheaper than paper manuals, it’s become a replacement for them. Microsoft has a very extensive Help file – but they have one big problem, for those of us looking for advanced features – their help files are all written as context-sensitive. So if you search by index, and find what you want – they refer to buttons and menus you can’t find because you’re not in ‘the context’. For this reason I find MS Bibles invaluable.

Anyone who reads a Read.me file has found out that this file usually defines new features, special steps for unique peripherals, and last-minute glitches which were caught after release. This is acceptable (well, maybe not…) for shrink wrap, but should never be a standard practice for developers.
In most companies, deployment includes:
- Change management notifications – informing the Change Management team of any impacts on user time, system down time, or other effects on the environment
- Track all calls on the new system for a week or two to see which are unique to the guy who downloads every possible game to his system, or which happen only on the Macintoshes, or which happen only on the non-clinical machines. The project is not closed until it is determined that all systems work smoothly.
- Change management is notified when the project is closed.
- If there is a problem with one type of environment (perhaps the financial department), the users must be notified, and they must be told of any workarounds you find.
- If the system must be uninstalled on any machines, Change Management must be notified, as well as the users.
What many texts do not handle in the implementation section is evaluation. This is tremendously important. Evaluation should be a lessons-learned affair, not a condemnation of any sort. If the system is in-house, determinations can be made of changes to include in subsequent versions. Team responsibilities can be viewed and honed. If the implementer is outside of the company, they too can figure out what works and what does not for that particular client. Evaluation should generate evolution.


 in Wunderlist")





