- HubPages»
- Technology»
- Computers & Software»
- Computer Software
enterprise database management

What is different about “enterprise”? Sheer volume and stress. As you may have noticed, Access isn’t really designed to be an Enterprise system, although it often is used as such, and successfully. An enterprise DBMS is one which serves a complete enterprise, be it a bunch of chain stores, a single warehouse, or a global institution. The amount of data involved is much more than just 35,000 records, usually (but not always), and there are usually a multiple of people accessing it at one time (hence the term stress, or load).
A multidimensional DBMS is organized around groups of records that share a common field value. The multidimensional database is for analyzing large groups of records. Remember the OLAP cube? OLAP is almost synonymous with multidimensional databases (which are often derived from relational databases.) in contrast, OLTP (On-Line Transaction Processing) is more often tied to relational DBMSs.
Data servers
A data server is a server dedicated to maintaining one or more databases; the server might also have portions of the DBMS on it. On the workstation (node, user) side is merely a means of accessing the data server. In the early days of networking there were only network servers and data servers – the data servers were usually Unix boxes, and often still are.
Distributed computing separates one application and splays its functions onto different computers on the network. These different computers may even be running on different operating systems. The advantage is twofold. For one, your word processor could keep functioning even though the thesaurus died. Another is that you could have a spell checker on one computer which can be used by not only the word processor, but also by the spreadsheet or a proprietary application. The drawback? Probably speed. To properly function, all systems must be running the same protocols – hence the entry of CORBA.
OLAP is more than just a conceptual cube. It is a whole group of software tools used to analyze data. It is used for multidimensional data and data mining. You would have an OLAP server, which serves as middleware between the user and the DBMS.
A data warehouse (DW) is a collection of data designed to support management decision-making. It usually has its own DBMS to access data from many views so the managers can view the business conditions from many views; it accesses databases across the enterprise.
In contrast, a data mart narrows the information to cover a particular topic or a particular department.
Data mining goes a little further by analyzing data to watch for trends and patterns for pro forma (predictive) behavior. This had been used for a long time for scientific, mathematical and research information, but it has become a ‘new’ buzz word as marketing companies offer this service for sales information (marketing trends), especially for Internet data. Data mining is not limited to one corporation’s systems – information may also be culled from the Internet (if you have access rights) or the World Wide Web (for public information).
Of course, what is the greatest enterprise of all? The world! Specifically the World Wide Web. (as opposed to the Internet). This means database servers (with ODBC, ADO and OLE), web servers (and learning about ASP and server-side programming), and browsers (and knowledge of HTML, Java and XML).
Database server architecture
According to Wikipedia, the three-tier architecture in one that is built on the traditional client-server architecture but breaks down the user interface, business logic, and data storage into three distinctly independent modules or platforms (Wikipedia, 2004). This is particularly useful in the enterprise environment where a system is highly stressed with huge amounts of data and users. Separating the business application into three distinct chunks that execute on three different computers (one client, one logic, one data) helps distribute the workload between three machines thereby reducing the stress on each machine while also speeding up the application.
In a tiered infrastructure, any given tier can only communicate with the tier above or below it.
A single-tier driver processes both ODBC calls and SQL statements. In other words, it converts the ODBC calls made by the application software into SQL statements that it then processes itself. A multi-tier driver processes ODBC calls and passes SQL statements to the data source. In other words, it sends the SQL statements it builds from the ODBC calls to another package that processes them and returns the results. While single-tier ODBC doesn't have to be done on a single machine and multi-tier doesn't have to be done in a client/server relationship, these are the most common applications of the two.
A two-tier architecture, sometimes called "client/server", indicates that two machines are involved in the use of a database. The first, the client, runs the application software, while the second, the server, holds the database files. They typically communicate over a network connection. The form of this communication is set by the method of ODBC access, or, more accurately, the type of drivers employed.
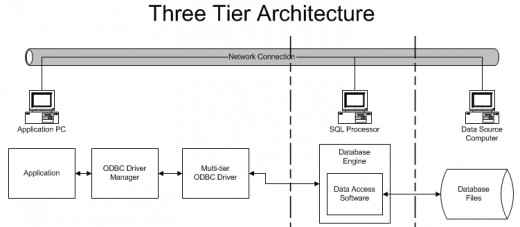
A three-tier architecture breaks the two-tier architecture and multi-tier driver configuration down even further, moving the SQL processing to a third machine.
This has its advantages, such as reducing the load on all three computers, but it can cause a lot of network traffic. In a 3-tier system, the tiers consist of the client system (such as a PC or terminal emulator), the application that the client system interfaces with, and the database which the application accesses. In this scenario, the client system doesn't directly access the database, but instead uses the application (possibly running on a completely different system) to present the data in an organized manner. The client can only communicate with the app server, the app server (which in a sense is middleware) can communicate with both the client and the data store, and the data store can only communicate with an app server. This ensures consistent handling of the data, and enforcement of business rules during any data access or update. . Some ODBC applications are, in fact, a three tier architecture. For example, we can develop an application (java, VB, etc), that will utilize the ODBC tools available to access the Universe Pick database (yes, Pick has come a long way since the 60's). In that scenario, the PC running the program is the client, the module on the RS6000 running the ODBC server is the application interface, and Universe is the database.
The relationship of tiers in the three tier architecture and tiers in ODBC is based, quite simply, on the number and types of connections the ODBC driver supports. The ODBC driver most often used in DBMSs is a single-tier "self contained" driver that includes all the functionality needed to manipulate the database. On the other hand, in a multi-tier ODBC driver, the ODBC driver merely interfaces with the DBMS allowing the database engine to do all the work of processing transactions. This type of ODBC driver also allows multiple connections to dissimilar DBMSs, allowing a single application to access data across several platforms (Brown, 2004).